Veri Bilimi İçin Ralli Maratonu Etap — 23.ipynb
Python Kütüphanelerine Giriş — Pandas — 4

Kaldığımız yerden devam edelim. Bir önceki örneğimizi bir hatırlayalım.


mean() ve median() metodunu describe() metodu ile ilişkisini görmekteyiz. Biz bu istatistiksel verileri NaN değerlerine atarsak daha mantıklı olur mu ? Elbette daha iyi olacaktır.
apply() :
apply() metodu kullanacağımız veriler için fonksiyon atamak için kullanmamız gereken bir metottur. İstersek def anahtar sözcüğü ile istersek de lambda isimsiz fonksiyonu ile oluşturup verimize atayabiliriz. Haydi bir örnekte görelim. Verilerimizin her bir sütun değerinin en büyük sayısal verisinden en küçük sayısal verisini çıkaran bir fonksiyon yazıp apply() metodu ile uygulayalım.

Görselimize baktığımızda benzer veriler olduğunu görüyoruz. Veri tablomuz az veriden oluştuğu için hangisinden kaç tane olduğunu söyleyebiliriz; ama daha fazla veriye sahip olduğumuzda bu durum pek mümkün olmayacaktır. Bu yüzden value_counts() metodunu kullanacağız.
value_counts():
Veri tablosunda her bir veriden kaç adet olduğunu gösterecektir. Daha detaylı anlamak için sütun değerini girmemiz yeterli olacaktır.

Yavaş yavaş verilerimizi daha iyi analiz edebilir hâle geliyoruz. Artık Merge işlemlerine geçebiliriz.
Merge:
Pandas kütüphanesinin bize sunduğu güzel olanaklardan bir tanesi ile daha karşı karşıyayız. Verileri birleştirme işlemlerinden concat() metodu ile başlayalım.
concat():
Artık verileri NumPy kütüphanesi ile rastgele oluşturarak işimizi kolaylaştırabiliyoruz. İki adet data frame yapısı oluşturalım ve concat() metodunu uygulayalım. Haydi örnek üzerinden görelim. Oluşturduğumuz projelerde sürekli data_frame değişkeni oluşturuyorduk. Bu değişkenin yerine data_frame kısaltılışını gösteren df değişkenini kullanalım.

Şimdi de bu iki veriyi birleştirelim.

Görsele baktığımızda her şey normal; ama satır bazlı indekslemede bir sorun var. Belli bir sıraya göre gitmiyor. Bunu nasıl düzeltebiliriz diye düşünürken, reset_index() metodu yardımımıza koşuyor. Haydi hemen düzeltelim.

İndeksleme düzeldi; fakat yeni bir index sütunu oluştu. Elbette bu sorun için de bir çözümümüz var. Yine aynı metot ve kullanacağımız metodun drop parametresini kullanmalıyız.

Başka bir diğer birleştirme olan join mantığı ile devam etmek istiyorum. join anahtar sözcüğünü daha çok veri tabanı birleştirme işleminde görmekteyiz. Hedefimiz veri bilimci olduğu için veri tabanı kısmına da değineceğiz.
Join:
Bu birleştirmenin mantığı sağ ve sol diye adlandırdığımız iki veri için ortak bir sütunda birleştirilmesidir. Örneğin sağ ve sol diye adlandırılan değişkenlerde aynı verilerden oluşan bir sütun bulunmaktadır. Amacımız ise bu iki veriyi birleştirirken ortak olan sütunun sabit kalmasıdır. Haydi bir örnek üzerinden daha iyi anlayalım.

Görselimize baktığımızda elimizde iki adet veri bulunmaktadır. Şimdi ise bu iki veriyi birleştirelim. Peki neden concat() metodunu kullanmadık? Hemen gösterelim neden kullanmadığımızı. :)

Şimdi ise join işlemi için merge metodunu kullanıp gösterelim.

Görsele baktığımızda “ on “ parametresini gözlemlemekteyiz. Bu parametrenin amacı birleştirme için ortak olan sütunu belirtir.
Gruplama
Verilerimizi gruplamanın bazı avantajları vardır.
→ Verileri bazı kriterlere göre gruplara ayırabiliriz.
→ Her gruba bağımsız olarak bir fonksiyon uygulayabiliriz.
→ Sonuçları bir veri yapısında birleştirebiliriz.
Gruplamayı groupby() metodu ile gerçekleştiririz.
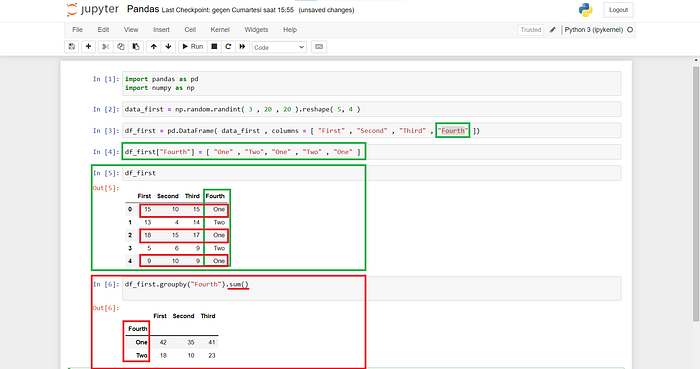
Birden fazla gruplama yapmak için liste içerisini alırız.

Pivot tables:
pivot() metodunun kullanım amacı ise seçeceğimiz bir sütun veya satırın daha detaylı ve bazı işlemler yapmasını sağlamaktadır. Örneğimiz ile devam edelim.

ilk örneğimizde, index parametresine “ Fourth “ sütununu index haline çevirdik. Kalan sütunlar ile de işlemlere devam edildi. “ First “, “ Second “ ve “ Third “ sütunlarının “ Fourth “ indeksi ile bağlantılı hale getirdik. “ One “ verisi görülen her bir değerin toplanılıp ortalaması alındı ve karşımıza dokuzuncu hücredeki sonuç döndürüldü.
Onuncu hücredeki örneğimizde index ve columns parametrelerine belirlediğimiz sütun değerlerini atadık. values parametresine ise “ Second “ sütununu atadık. İndex değerimiz “ Fourth” columns değerimiz “ First ” ve bunlara ile ortak çalışacak olan değerimizi ise “ Second ”. First sütununa baktığımızda “ 6 ” değerimiz “ Two ” verisinde ; “ Second “ ile bağlantılı olarak “ 18 ” verisini gözlemlemekteyiz. Birden fazla değer olanların ise ortalaması alınıp onuncu hücre çıktısında görebiliriz.
Bu yazımızda pandas kütüphanelerinde bir diğer işimize yarayan bazı metotlara değindik. Diğer yazımızda pandas kütüphanelerinde ele alacağımız son metotlar olacaktır. pandas kütüphanesi ile farklı formatlarda ki dosyaları okuyabileceğiz.
Bir diğer yazımızda görüşmek üzere.
